Lo Structured Query Language (SQL) è uno degli elementi costitutivi fondamentali della moderna architettura di database. SQL definisce i metodi utilizzati per creare e manipolare database relazionali su tutte le principali piattaforme. A prima vista, il linguaggio può sembrare intimidatorio e complesso, ma non è poi così difficile.
Informazioni su SQL
La corretta pronuncia di SQL è una questione controversa all'interno della comunità dei database. Nel suo standard SQL, l'American National Standards Institute ha dichiarato che la pronuncia ufficiale è "es queue el." Tuttavia, molti professionisti del database hanno adottato la pronuncia gergale "sequel". di GIF, non c'è una risposta giusta.
SQL è disponibile in molte versioni. I database Oracle utilizzano il suo PL/SQL proprietario. Microsoft SQL Server utilizza Transact-SQL. Tutte le variazioni si basano sullo standard ANSI SQL del settore.
Questa introduzione utilizza comandi SQL conformi ad ANSI che funzionano su qualsiasi moderno sistema di database relazionale.
DDL e DML
I comandi SQL possono essere suddivisi in due sottolinguaggi principali. Il linguaggio di definizione dei dati contiene i comandi utilizzati per creare e distruggere database e oggetti di database. Dopo che la struttura del database è stata definita con DDL, gli amministratori e gli utenti del database possono utilizzare il Data Manipulation Language per inserire, recuperare e modificare i dati in esso contenuti.
SQL supporta un terzo tipo di sintassi chiamato Linguaggio di controllo dei dati. DCL regola l'accesso di sicurezza agli oggetti all'interno del database. Ad esempio, a Script DCL concede o revoca a specifici account utente il diritto di leggere o scrivere su tabelle all'interno di una o più aree definite del database. Nella maggior parte degli ambienti multiutente gestiti, gli amministratori di database di solito eseguono script DCL.
Comandi del linguaggio di definizione dei dati
Il linguaggio di definizione dei dati viene utilizzato per creare e distruggere database e oggetti di database. Questi comandi vengono utilizzati principalmente dagli amministratori di database durante le fasi di installazione e rimozione di un progetto di database. DDL ruota attorno a quattro comandi principali:creare, uso, alterare, e far cadere.
Creare
Il creare Il comando stabilisce database, tabelle o query sulla tua piattaforma. Ad esempio, il comando:
CREARE BANCA DATI dipendenti;
crea un database vuoto chiamato dipendenti sul tuo DBMS. Dopo aver creato il database, il passaggio successivo consiste nel creare tabelle che contengano dati. Un'altra variante del creare comando realizza questo scopo. Il comando:
CREATE TABLE personal_info (first_name char (20) not null, last_name char (20) not null, impiegato_id int not null);
stabilisce una tabella intitolata informazioni personali nella banca dati corrente. Nell'esempio, la tabella contiene tre attributi: nome di battesimo, cognome, e ID Dipendente insieme ad alcune informazioni aggiuntive.
Uso
Il uso comando specifica il database attivo. Ad esempio, se stai attualmente lavorando nel database delle vendite e desideri impartire alcuni comandi che influenzeranno il database dei dipendenti, precedili con il seguente comando SQL:
USE dipendenti;
Ricontrolla il database in cui stai lavorando prima di emettere comandi SQL che manipolano i dati.
Alter
Dopo aver creato una tabella all'interno di un database, modificarne la definizione tramite il pulsante alterare comando, che modifica la struttura di una tabella senza eliminarla e ricrearla. Dai un'occhiata al seguente comando:
ALTER TABLE personal_info ADD stipendio denaro nullo;
Questo esempio aggiunge un nuovo attributo alla tabella personal_info: lo stipendio di un dipendente. Il i soldi L'argomento specifica che lo stipendio di un dipendente viene archiviato utilizzando un formato dollari e centesimi. Infine, il nullo La parola chiave indica al database che è possibile che questo campo non contenga alcun valore per un determinato dipendente.
Far cadere
Il comando finale del linguaggio di definizione dei dati, far cadere, rimuove interi oggetti di database dal nostro DBMS. Ad esempio, per rimuovere definitivamente la tabella personal_info che abbiamo creato, usa il seguente comando:
DROP TABLE info_personali;
Allo stesso modo, il comando seguente verrebbe utilizzato per rimuovere l'intero database dei dipendenti:
DROP DATABASE dipendenti;
Usa questo comando con cautela. Il far cadere Il comando rimuove intere strutture di dati dal database. Se vuoi rimuovere singoli record, usa il pulsante Elimina padronanza del linguaggio di manipolazione dei dati.
Comandi del linguaggio di manipolazione dei dati
Il linguaggio di manipolazione dei dati viene utilizzato per recuperare, inserire e modificare le informazioni del database. Questi comandi DML offrono la struttura tipica per interagire all'interno del database su base routinaria.
Inserire
Il inserire Il comando aggiunge record a una tabella esistente. Tornando all'esempio personal_info della sezione precedente, immagina che il nostro dipartimento delle risorse umane debba aggiungere un nuovo dipendente al suo database. Usa un comando simile a questo:
INSERISCI IN info_personali
valori('bart','simpson',12345,$45000);
Notare che ci sono quattro valori specificati per il record. Questi corrispondono agli attributi della tabella nell'ordine in cui sono stati definiti: nome di battesimo, cognome, ID Dipendente e stipendio.
Selezionare
Il Selezionare command è il comando più comunemente usato in SQL. Recupera informazioni specifiche da un database operativo. Dai un'occhiata ad alcuni esempi, sempre usando la tabella personal_info dal database dei dipendenti.
Il comando mostrato di seguito recupera tutte le informazioni contenute nella tabella personal_info. L'asterisco è un carattere jolly in SQL.
SELEZIONARE *
DA info_personali;
In alternativa, limitare gli attributi che vengono recuperati dal database specificando che cosa viene selezionato. Ad esempio, il reparto Risorse umane potrebbe richiedere un elenco dei cognomi di tutti i dipendenti dell'azienda. Il seguente comando SQL recupera solo quelle informazioni:
SELECT cognome
DA info_personali;
Il dove La clausola limita i record recuperati a quelli che soddisfano i criteri specificati. Il CEO potrebbe essere interessato a rivedere i registri del personale di tutti i dipendenti altamente retribuiti. Il comando seguente recupera tutti i dati contenuti in personal_info per i record che hanno un valore di stipendio maggiore di $ 50.000:
SELEZIONARE *
DA info_personali
WHERE stipendio > $ 50000;
Aggiornare
Il aggiornare Il comando modifica le informazioni contenute in una tabella, in blocco o singolarmente. Supponiamo che l'azienda dia a tutti i dipendenti un aumento del costo della vita del 3% ogni anno. Il seguente comando SQL applica questo bump a tutti i dipendenti archiviati nel database:
AGGIORNAMENTO personal_info
SET stipendio = stipendio * 1,03;
Quando il nuovo dipendente Bart Simpson dimostra prestazioni al di sopra e al di là del dovere, la direzione desidera riconoscere i suoi successi stellari con un aumento di $ 5.000. La clausola WHERE individua Bart per questo rilancio:
AGGIORNAMENTO personal_info
SET stipendio = stipendio + 5000
DOVE id_impiegato = 12345;
Elimina
Infine, diamo un'occhiata al Elimina comando. Scoprirai che la sintassi di questo comando è simile a quella degli altri comandi DML. Il comando DELETE, con a dove clausola, rimuovere un record da una tabella:
ELIMINA DA personal_info
DOVE id_impiegato = 12345;
DML supporta anche i campi aggregati. In un Selezionare istruzione, operatori matematici come somma e contare riepilogare i dati all'interno di una query. Ad esempio, la domanda:
seleziona count(*) from personal_info;
conta il numero di record nella tabella.
Join di database
UN aderire L'istruzione combina i dati in più tabelle per elaborare in modo efficiente grandi quantità di dati. Queste dichiarazioni sono dove risiede la vera potenza di un database.
Per esplorare l'uso di una base aderire operazione per combinare i dati di due tabelle, continuare con l'esempio utilizzando la tabella personal_info e aggiungere una tabella aggiuntiva al mix. Supponi di avere un tavolo chiamato azione disciplinare che è stato creato con la seguente dichiarazione:
CREATE TABLE azione_disciplinare (id_azione int not null, id_impiegato int non null, char commenti (500));
In questa tabella sono riportati gli esiti dei provvedimenti disciplinari per i dipendenti della società. Non contiene alcuna informazione sul dipendente oltre al numero del dipendente.
Supponiamo che tu sia stato incaricato di creare un rapporto che elenchi le azioni disciplinari intraprese nei confronti di tutti i dipendenti con uno stipendio superiore a $ 40.000. L'uso di un'operazione JOIN, in questo caso, è semplice. Recupera queste informazioni usando il seguente comando:
SELECT info_personale.nome, info_personale.cognome, azione_disciplinare.commenti
FROM personal_info INNER JOIN discipline_action ON personal_info.employee_id = discipline_action.employee_id
WHERE info_personale.salario > 40000;
Tipi di join
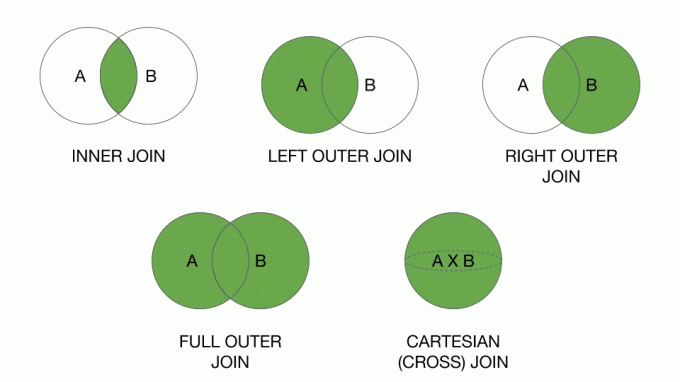
I join sono disponibili in diversi gusti. Nell'istruzione SQL, la prima tabella (di solito chiamata Tabella A o il Tavolo a sinistra) si unisce alla seconda tabella (di solito chiamata Tabella B o il Tavolo destro) in modo consapevole della posizione. Pertanto, se si modifica l'ordine delle tabelle nell'istruzione join, i risultati dell'operazione saranno diversi. I principali tipi di join includono:
- unione interna: corrisponde solo ai record in cui il sopra condizione corrisponde agli stessi record in entrambe le tabelle.
- unione esterna: corrisponde solo ai record di entrambe le tabelle che escludere i risultati individuati nel sopra condizione.
- Unisciti a destra: Corrisponde a tutti i record della tabella B più i record della tabella A che corrispondono a sopra condizione.
- Unisciti a sinistra: Corrisponde a tutti i record della tabella A più i record della tabella B che corrispondono a sopra condizione.
- Unione incrociata: corrisponde a tutti i record come se le tabelle fossero identiche. Questo processo genera qualcosa chiamato prodotto cartesiano. Spesso, i cross-join sono sgraditi, perché corrispondono a ogni riga della tabella A, individualmente, con ogni riga della tabella B. Pertanto, se la tabella A offriva cinque record e la tabella B offriva 9 record, una query cross-join offre 45 righe risultanti.